Case Study: Confusion Matrix in Cyber Security(Phishing Attack)

What is Phishing Attack?
Phishing is a type of social engineering attack often used to steal user data, including login credentials and credit card numbers. It occurs when an attacker, masquerading as a trusted entity, dupes a victim into opening an email, instant message, or text message. The recipient is then tricked into clicking a malicious link, which can lead to the installation of malware, the freezing of the system as part of a ransomware attack or the revealing of sensitive information.
Phishing Detection Using Machine Learning Techniques
Although many methods have been proposed to detect phishing websites, Phishers have evolved their methods to escape from these detection methods. Phishers try to deceive their victims by social engineering or creating mock-up websites to steal information such as account ID, username, password from individuals and organizations. One of the most successful methods for detecting these malicious activities is Machine Learning. This is because most Phishing attacks have some common characteristics which can be identified by machine learning methods.
So after building a machine learning model and trained it on some data of Phishing attacks … now what? How to evaluate the accuracy of the model?
Before going further, let’s build up the scenario first.
Consider a scenario in which we have to detect the sites which are potentially a phishing site. We have created an AI system which is detecting the sites provided to it and then classifying them into Phishing sites and Genuine sites. Here, the Genuine site is considered Negative and the Phishing site is considered Positive.
Now, Suppose 1000 sites are passed to the model which the user has visited for the entire week and it includes both the genuine and potential phishing sites also.
Our Machine Learning model has classified the following:
Total sites passed: 1000Sites clasified as Genuine -> 940Sites classified as Phising -> 60
After further investigation into the matter, we found that:-
The ground trush is: -> Out of those 940 sites which were classified as genuine sites, 900 of them were actually genuine sites. -> Out of those 60 sites which were classified as phishing sites, 50 of them were actually phishing sites.
Now, will be evaluating our Model’s Predictions with respect to its Ground Truth. Our machine learning model is performing binary classification and we could use several metrics and plots to gather insights on the performance of our model. One of these evaluation metrics is the Confusion Matrix.
A confusion matrix is a table that allows visualization of the performance of an algorithm. Let’s look at what a confusion matrix looks like:-

It’s a 2X2 Grid. The Columns represent the classes of the Ground Truth whereas the Rows represent the classes of the Predictions. A confusion matrix is a technique for summarizing the performance of a classification algorithm. There are 4 cells — TP, FP, FN, TN.
Let’s relate this table with our application…
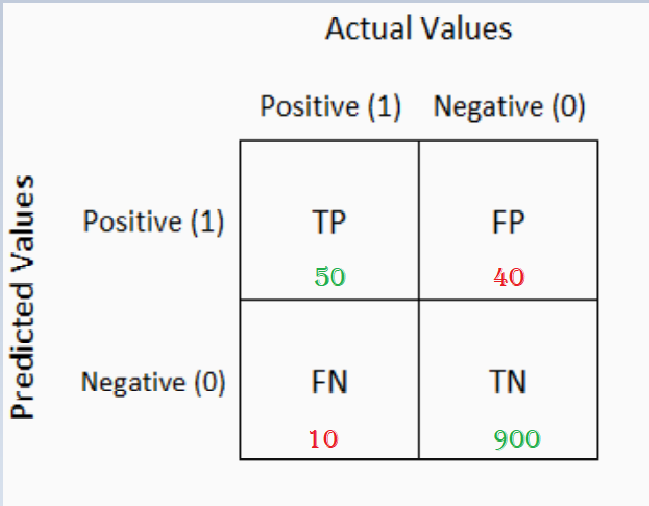
Let’s dig into this matrix…
- Out of 1000 sites, our model predicted 60 sites as phishing out of which 50 were phishing sites.
- Out of 1000 sites, our model predicted 940 sites as genuine, out of which 900 were genuine.
TP — True Positives
True Positive is the total number of sites that were correctly classified as Phishing sites.
TN — True Negatives
True Negative is the number of total sites that were correctly classified as Genuine sites.
FP — False Positives
False Positives is the number of total sites that were phishing sites but were classified as genuine by the model.
This is known as Type 1 error —
FN — False Negatives
False Negatives are the number of total records that were genuine but were classified as phishing by the model.
This is known as Type 2 error
Which error is potentially more dangerous and why?
Let’s look at what potential threats the two of these posses…
In the Type II error, the model classified a site(genuine) to be phishing. In this case, we could further investigate the site to find out that this site was genuine and we could potentially drop this concern.
But in the case of Type I error, we classified a phishing site as a genuine site. This means that the user has visited the phishing site considering it to be genuine and thereby he could have compromised his security and critical personal data. Thus, it is very crucial to keep this error as low as possible as it’s very dangerous.
Thank you EveryOne For reading .!!